2023 年度 データベースII : InfluxDB のインストールと利用
はじめに
InfluxDB は大量の時系列データ (時刻と値の組み合わせデータ) を蓄積・活用するために最適化されたオープンソースのデータベースである. IoT で行われるような絶え間なく送られて送るセンサーデータを取り扱うのに向いていると言われている.
InfluxDB では Flux という問い合わせ言語が実装されている. InfluxDB はリレーショナルデータベースではないが, SQL に似た InfluxQL という独自の問い合わせ言語も利用することができる.
マニュアルなど
参考
データ構造の特徴
データ構造を決め打ちしているところが大きな特徴である. 後述するデータ入力用の csv ファイルの中身を確認するのがわかりやすいが, データには必ず _time (時刻), _value (値), _field (温度,湿度など), _measurement (RDBMS のテーブルに相当) が必要となっている.
host,_time,_value,_field,_measurement cps00,2020-09-24T11:16:00Z,23.26,temperature,myroom cps00,2020-09-24T11:17:00Z,23.14,temperature,myroom cps00,2020-09-24T11:18:00Z,23.2,temperature,myroom cps00,2020-09-24T11:19:00Z,23.44,temperature,myroom cps00,2020-09-24T11:20:00Z,23.42,temperature,myroom ...(略)...
RDBMS に当てはめて考えると,_measurement というテーブルの中に _time, _field, _value というカラムがあり,そこに 時刻・センサーの種別・センサーの値が保存されていると見做すことができる.
用語
- measurement : リレーショナルデータベースのテーブルに相当するもの
- Bucket : リレーショナルデータベースのデータベースに相当するもの
- organization : bucket は 1 つの organization に所属する.
InfluxDB のインストール
Debian パッケージで提供されている InfluxDB は ver. 1.6 となっており, だいぶ古い.ここでは 2023/06/06 時点で最新の ver. 2.7 をインストールすることにする. 以下では公式のインストールガイド に従って作業を行う.
Influxdb のソースファイルをダウンロードする.curl は influxdb2 をインストールするために必要なので先にインストールしている.
$ sudo -s # apt update # apt install curl # cd /usr/local/src # wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.0-amd64.deb # dpkg -i influxdb2-2.7.0-amd64.deb
起動および確認."active (running)" になっていれば OK.
# systemctl enable influxdb (再起動時に自動起動する設定) # systemctl start influxdb (起動) # systemctl status influxdb (ステータスの確認) ● influxdb.service - InfluxDB is an open-source, distributed, time series database Loaded: loaded (/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2023-06-06 15:22:56 JST; 3s ago <-- この行に注目 ...(以下略)...
InfluxDB のバージョンの確認.
# influxd version InfluxDB v2.7.0 (git: 85f725f8b9) build_date: 2023-04-05T15:32:25Z # exit $
InfluxDB のセットアップ
公式の「Set up InfluxDB」 に従ってセットアップを行う.
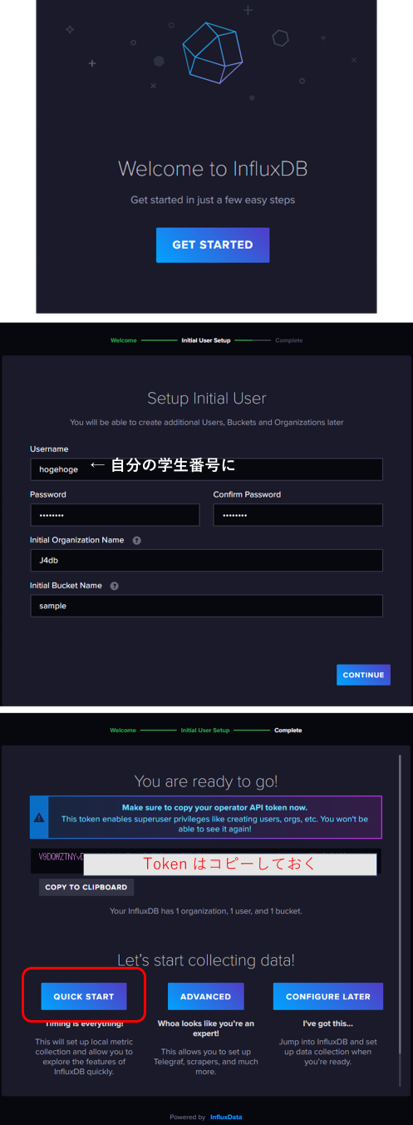
Web ブラウザ上でセットアップしてみる.http://10.176.0.1XX:8086 にアクセスすること (XX は自分の VM に合わせて設定すること).但し,表示された Token は必ずコピーしておくこと.
次に作成した Organization : J4db と bucket : sample にサンプルデータを投入する. 下図のように選択していき,
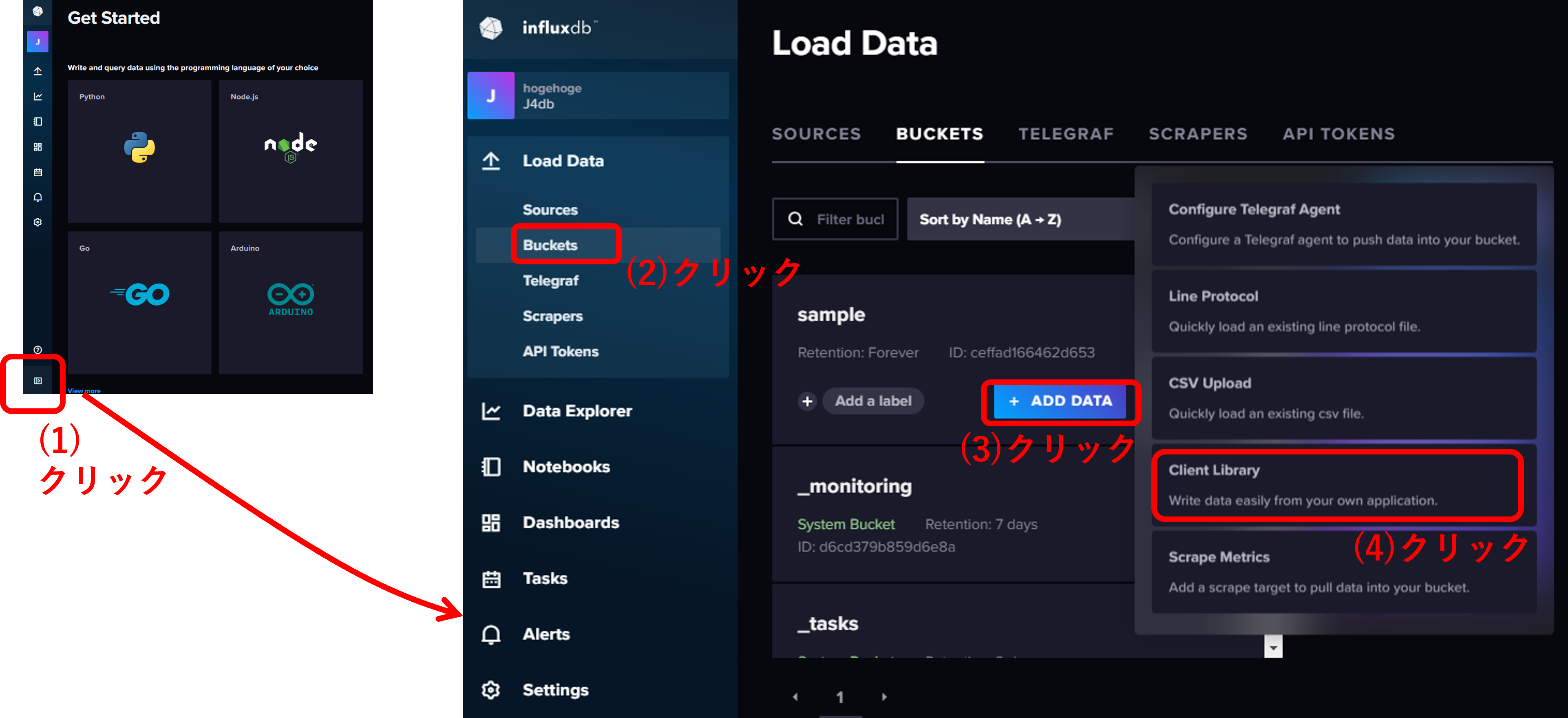
InfluxDB CLI (コマンドラインインターフェイス) を選択する.
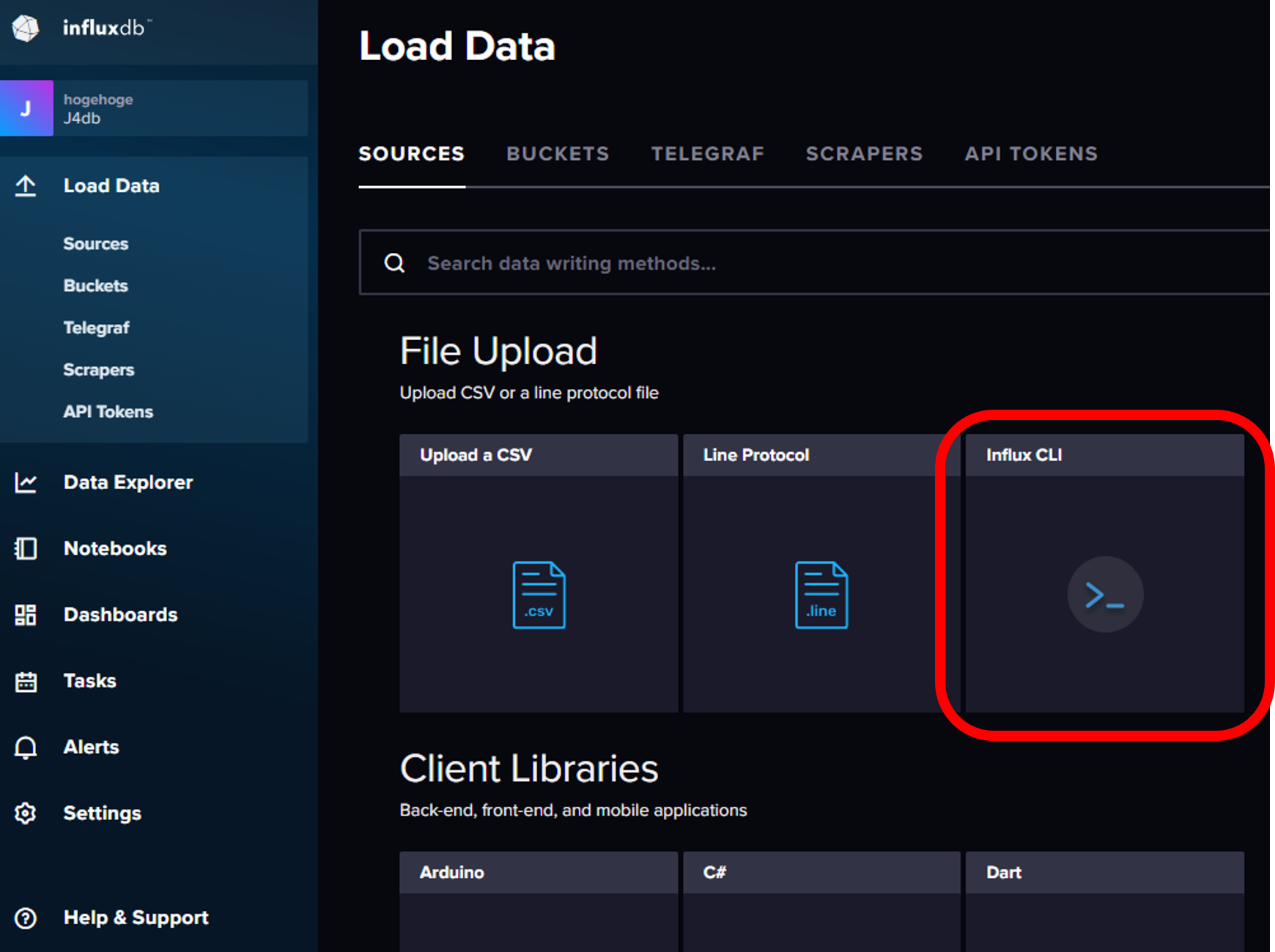
overview
YouTube ビデオ を眺めてみると良い.
Install Dependencies
Linux をクリックして,その指示に従って influxdb-client をインストールする. 但し,ダウンロードが指示されているパッケージが ver. 2.3 で若干古いので, ここでは ver. 2.7 をダウンロードして使うことにする.
$ sudo -s # cd /usr/local/src # wget https://dl.influxdata.com/influxdb/releases/influxdb2-client-2.7.3-linux-amd64.tar.gz # tar zxvf influxdb2-client-2.7.3-linux-amd64.tar.gz # mv influx /usr/local/bin/ # exit
Initialize Client
プロファイルを作る.組織 (org) 名など,大文字小文字の区別があるので注意.
$ influx config create --config-name myprofile \
--host-url "http://10.176.0.148:8086" # URL は自分の VM にすること
--org j4db \ # Web で作成したものを指定.
--token XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX== \ # コピーしておいた Token をコピペ
--active
Active Name URL Org
* myprofile http://localhost:8086 j4db
Write Data
サンプル csv データの入力. "URL to file" をクリックして表示されたコマンドを入力する.
$ influx write --bucket sample \ --url https://influx-testdata.s3.amazonaws.com/air-sensor-data-annotated.csv
補足
ローカルに保存されている csv ファイルを入力する場合は以下のようにする.
$ wget https://influx-testdata.s3.amazonaws.com/air-sensor-data-annotated.csv $ influx write --bucket j4db --file air-sensor-data-annotated.csv
確認 (Flux)
コマンドラインでデータが入力されたか確認する.
$ influx query 'from(bucket:"sample") |> range(start:-30m)'
次に,ブラウザ上でも確認する.ブラウザではグラフも作ってくれるので便利である.
左カラムで "Data Explore" を選択し,Bucket : sample の中の Measurement に airSensors (サンプルファイルで入力したもの) があるか確認する.あれば, 以下の図のようにデータを書いてみる.
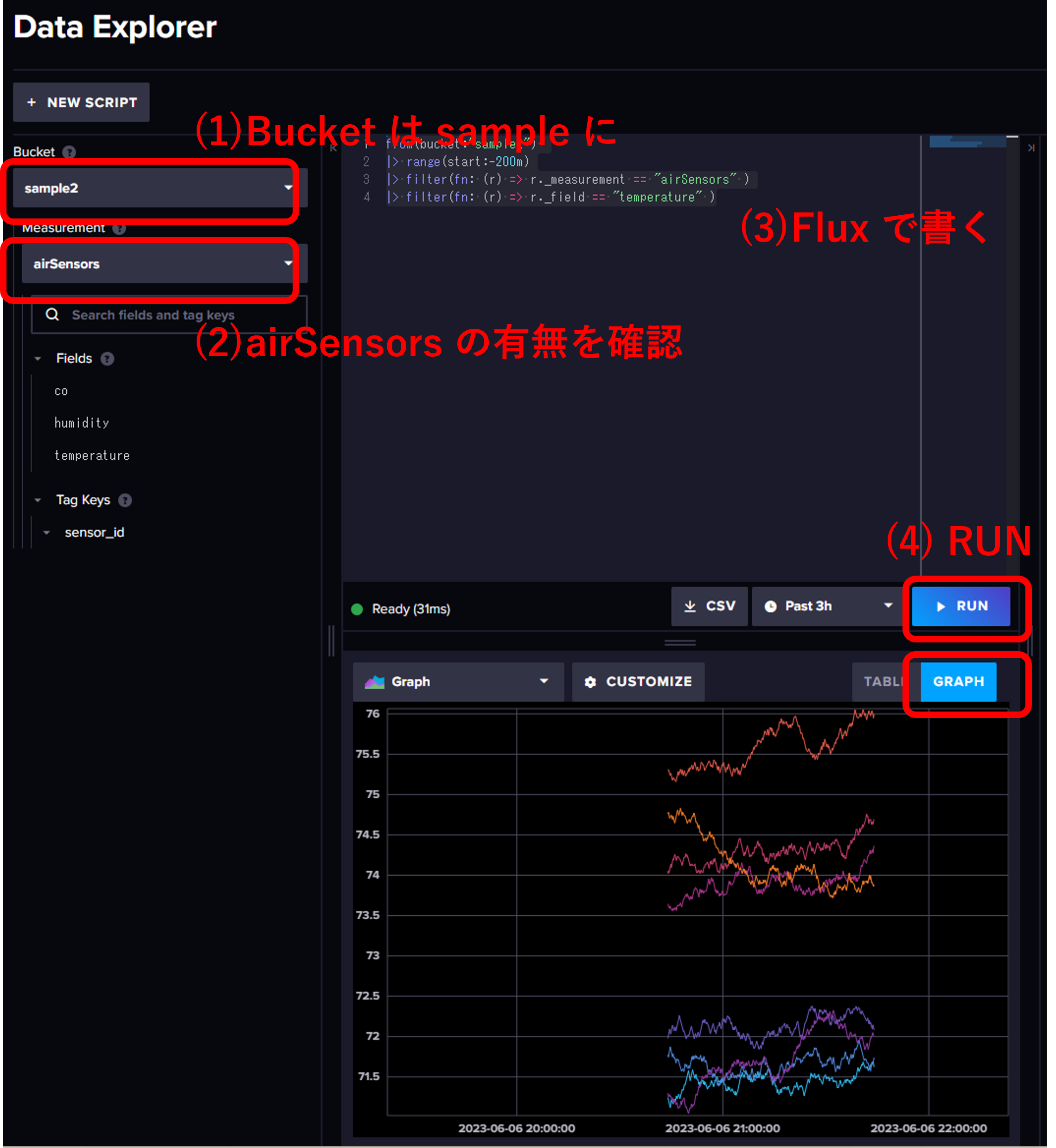
なお,上図において Flux で以下の命令を書いた.
from(bucket:"sample2") |> range(start:-200m) |> filter(fn: (r) => r._measurement == "airSensors" ) |> filter(fn: (r) => r._field == "temperature" )
確認 (InfluxQL)
コマンドラインで InfluxQL でデータを確認するときは以下のようにすると良い. influx コマンドで v1 shell を指定すると,SQL と同様なコマンド体系 (InfluxQL) が利用できる.
$ influx v1 shell > show databases > use sample > select * from airSensors
課題
内容
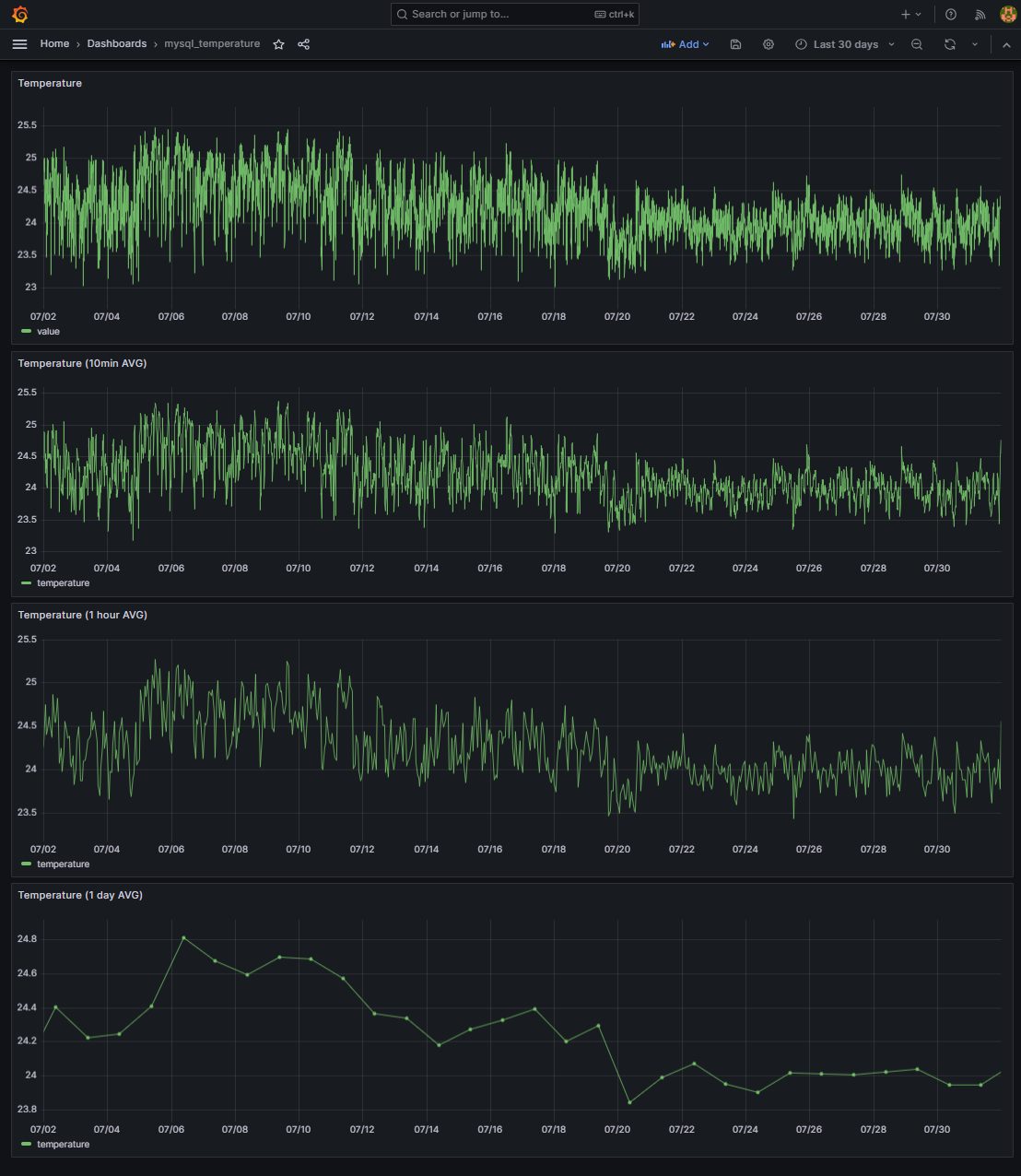
InfluxDB でデータの新たな bucket (sample2) を作成し, そこに CSV ファイルよりにデータを入力しなさい. そして influxDB で以下の移動平均を行った結果をグラフ化し, そのスナップショットを提出しなさい (URL バーを必ず含めること).
- 10 分平均値 (前 10 分平均) →10:10 の値は 10:00~10:10 の平均値とする.
- 60 分平均値 (10 分間隔のデータから, 毎正時の値を抽出) →10:00 の値は 09:50~10:10 の平均値とする.
- 1 日ごとの平均値・最大値・最小値・標準偏差
なお,この移動平均の取り方は, 気象観測統計の解説 を参照している.
やり方
CSV からのデータ入力
データを取得して,influxDB に入力する.
$ wget https://www.gfd-dennou.org/arch/iotex/oss/IoTeX_2023/myroom_influxdb.csv $ influx bucket create --name my_monitotring -c myprofile $ influx write --bucket my_monitoring --file myroom_influxdb.csv
データ表示
ブラウザ上でデータを表示してみる.
from(bucket:"my_monitoring") |> range(start:-3y) |> filter(fn: (r) => r._measurement == "myroom" ) |> filter(fn: (r) => r._field == "temperature" )
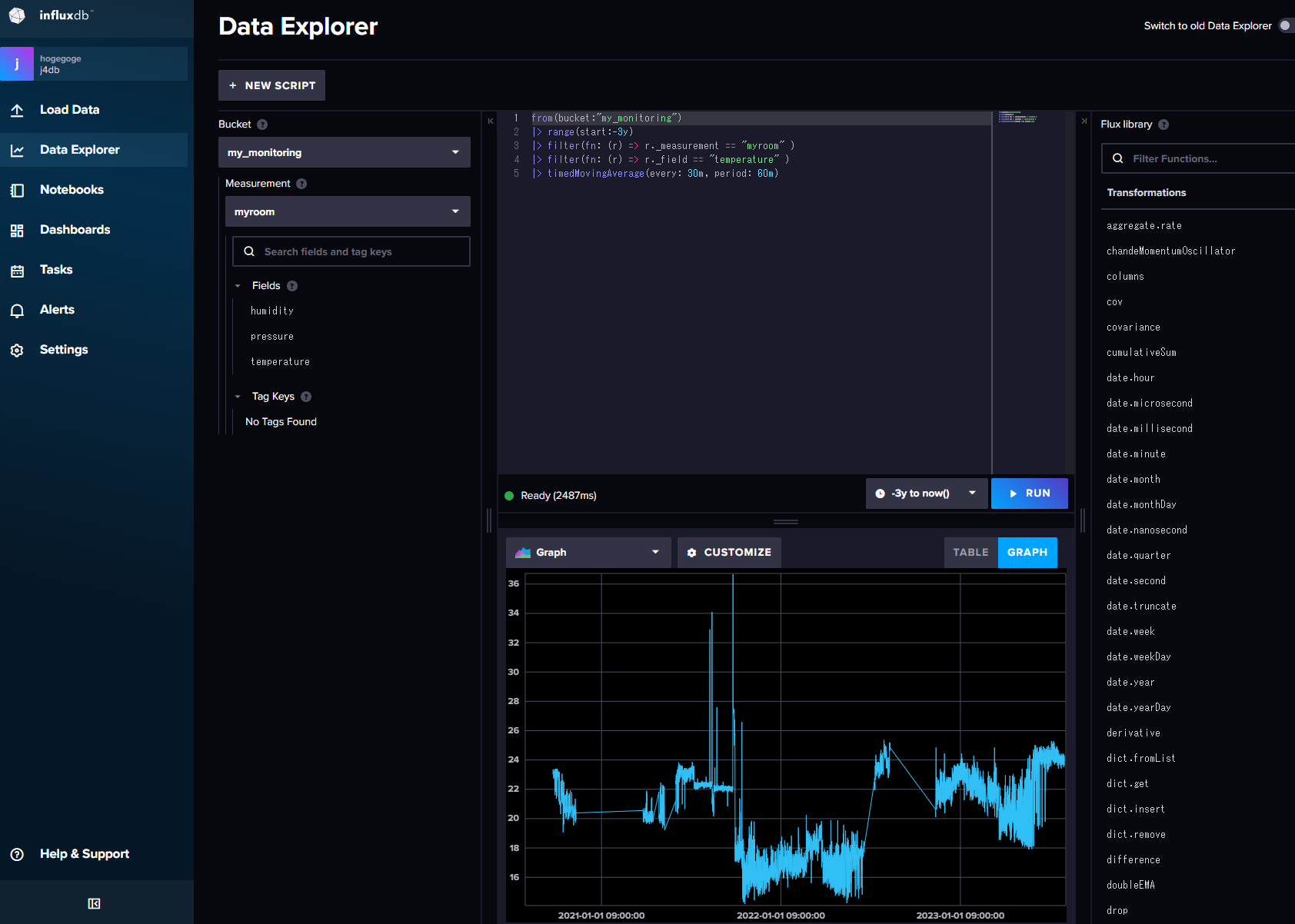
移動平均
移動平均は mariaDB では組み込み関数が無く,それゆえ influxDB の 方が扱いやすい. 移動平均 や Window and aggregate といった機能を用いて実行することができる.
発展
Grafana のインストールを行い,Grafana 上で MariaDB と InfluxDB をソースとしてデータを表示せよ.